Spark — Linux环境安装¶
要求¶
这里演示如何在Linux中安装Spark单机版。和在Windows一样,安装Spark需提前安装Java 8或更高版本,参考Spark — Windows环境安装。
下载Spark¶
访问Spark下载页下载Apache Spark压缩包。 可以使用下拉框选择不同版本的Spark和Hadoop,然后点击第三行获取下载链接。
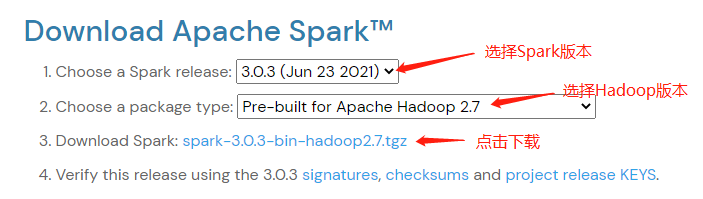
ApacheSpark下载页¶
在命令行使用 wget 命令下载:
wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz
下载完成后解压至目录 /opt/spark:
tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz
mv spark-3.0.3-bin-hadoop2.7 /opt/spark
配置环境变量¶
配置Spark环境变量:
[root@bigdata-app]$ vim ~/.bashrc
# 在文件中加入下面两行.
export SPARK_HOME=/opt/spark/spark-3.0.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
然后运行下面命令使环境变量生效:
source ~/.bashrc
验证¶
至此Spark已完成在Linux机器上的安装,可以运行 spark-shell 验证是否安装完成,也可以使用 spark-submit 运行一个Spark例子:
spark-submit --class org.apache.spark.examples.SparkPi /opt/spark/spark-3.0.3-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.3.jar 10