Spark — Windows环境安装¶
安装Java¶
Windows上安装Apache Spark需要Java 8或更高版本,你可以从 Oracle 下载相应的Java版本然后安装。 使用OpenJDK可以从这里下载。
下载安装后,请参考Java安装教程配置好环境变量。
Note
本文使用的环境是Java8,同样的步骤也适用于Java11和13版本。
安装Spark¶
访问Spark下载页下载Apache Spark压缩包。 可以使用下拉框选择不同版本的Spark和Hadoop,然后点击第三行的下载链接即可下载。
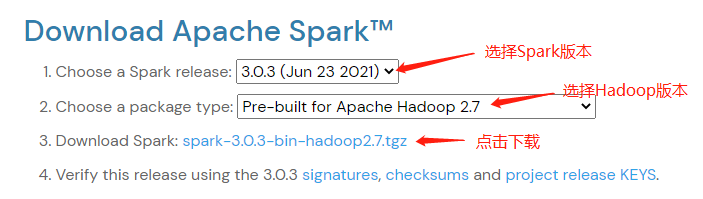
ApacheSpark下载页¶
下载完成后使用解压工具(推荐7zip)将其解压,然后将解压后的目录 spark-3.0.3-bin-hadoop2.7
复制到 C:\opt\spark-3.0.3-bin-hadoop2.7 。
配置环境变量¶
Windows上安装Apache Spark需要配置 Java_HOME(安装Java时配置)、 Spark_HOME 、 HADOOP_HOME 和 PATH 环境变量。
根据安装目录需要做如下配置:
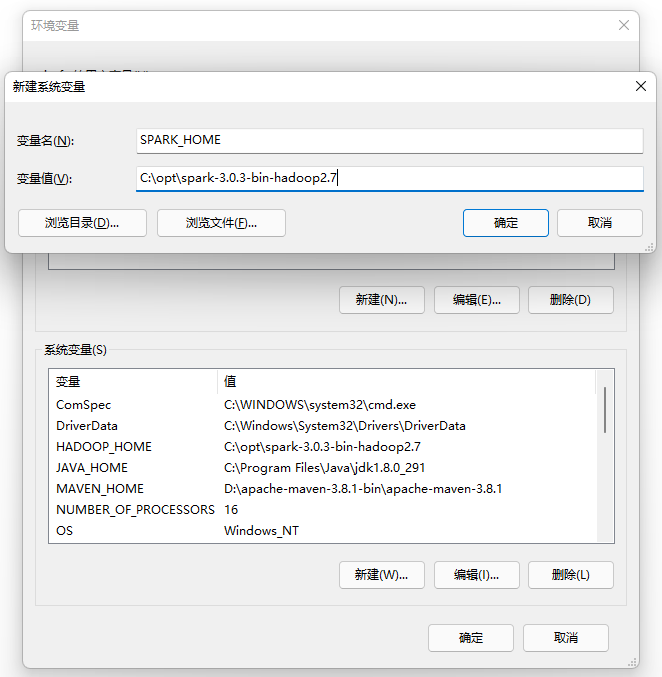
SPARK_HOME = C:\opt\spark-3.0.3-bin-hadoop2.7
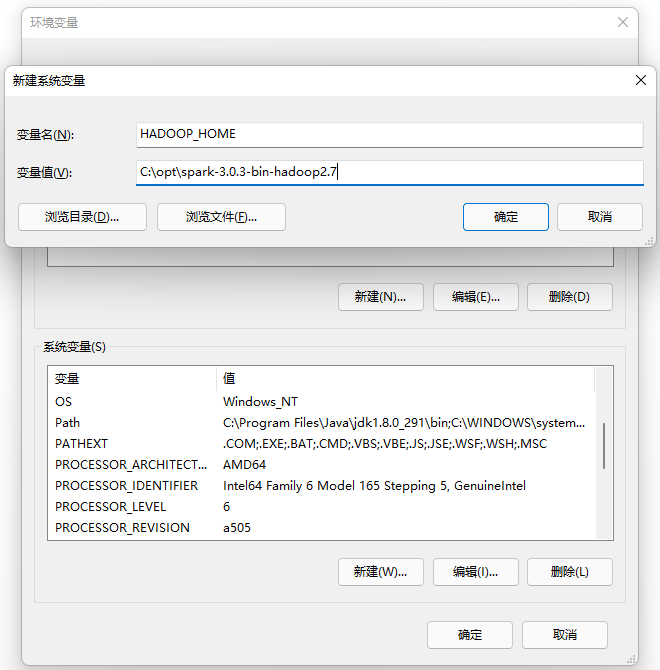
HADOOP_HOME = C:\opt\spark-3.0.3-bin-hadoop2.7
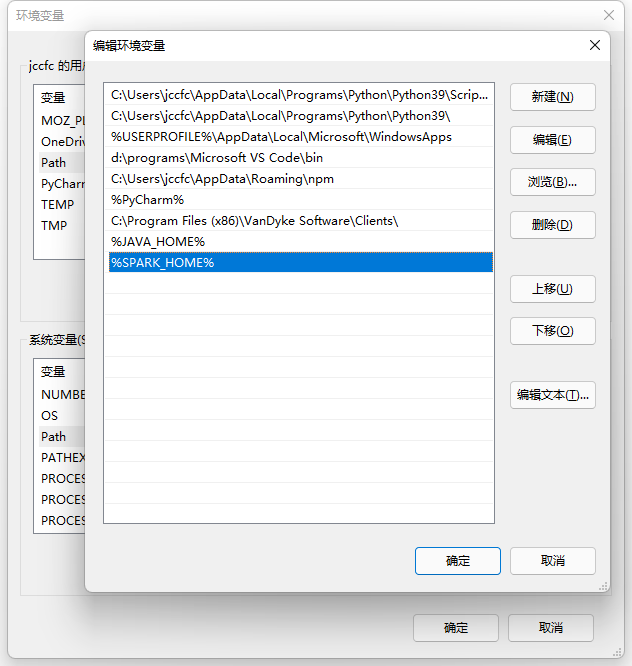
PATH=%PATH%;%SPARK_HOME%
新建环境变量 SPARK_HOME:
新建环境变量 HADOOP_HOME:
将 %SPARK_HOME% 添加至环境变量 PATH 中:
安装 winutils.exe¶
要在Windows上运行Apache Spark,还需要下载 winutils.exe,可以到这里自行下载对应Hadoop版本的winutils包,然后将其内容复制到 %SPARK_HOME%\bin 目录下。
Note
Hadoop的版本可以在 %SPARK_HOME% 目录中的 RELEASE 文件中看到。
Spark shell¶
Spark shell是Spark发行版中附带的CLI工具。在配置好环境变量后, 在命令行中运行命令 spark-shell 即可打开Spark shell交互式命令行工具。
Spark Shell Command Line¶
默认情况下,spark-shell同时还会拉起一个Web页面,在本例中为http://host.docker.internal:4040 , 可以在浏览器中直接打开。实际地址请详见spark-shell的输出提示。
在spark-shell的命令行中可以运行一些spark语句,如创建RDD、获取spark版本等。
scala> spark.version
res0: String = 3.0.3
scala> val rdd = sc.parallelize(Array(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24