Spark RDD — Stage¶
Spark Stage是计算多个任务的物理执行单元。 Spark处理数据时会根据RDD的依赖关系构建一个有向无环图(DAG),然后根据DAG划分Stage, 在运行时按照步骤执行DAG中的Stage。
DAG¶
有向无环图:DAG(Directed Acyclic Graph)是什么?:
Directed:节点间由边连接在一起,连接顺序由RDD上的调用顺序决定。
Acyclic:节点不能连接成环;即如果操作或转换一旦完成,则无法还原回其原始值。
Graph:Graph指由边和点排列形成的特定图形。点为RDD,边为RDD上调用的算子。
DAGScheduler将Stage划分为多个任务,然后将Stage信息传递给集群管理器,集群管理器触发任务调度器运行任务。 Spark驱动程序将逻辑执行计划转换为物理执行计划。Spark作业以流水线方法执行。
WordCount例子¶
下面是一个Spark入门级的程序WordCount:
val sc = spark.sparkContext
sc.textFile("src/main/resources/test.txt")
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_+_)
.saveAsTextFile("src/main/resources/result")
程序解释:
textFile(...): 读取本地文本文件 test.txt ;flatMap(...): 将文件中的内容拆分成每个词 ;map(...): 将每个词处理成 (word, 1) ,方便后续计数统计 ;reduceByKey(...): 按 key 将 value 累加得到每个 key 的数量 ;saveAsTextFile(...): 将计算结果写入到本地目的 result ;
Spark应用程序其实就是基于RDD的一系列计算操作,可以在SparkUI上看到如下DAG图:
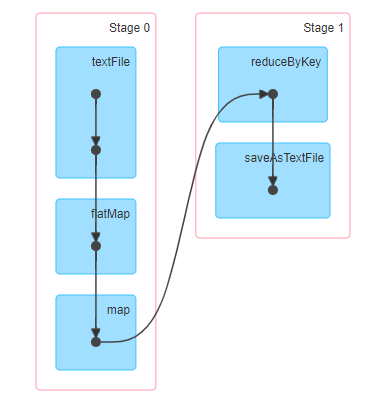
WordCount DAG¶
从图中可以出,WordCount程序中的5个操作算子被分成了两个Stage。
RDD依赖关系¶
Spark中每个转换算子都会生成一个新的RDD,这样在一系列RDD中就形成了一种前后依赖关系。 RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),下图展示了两种依赖之间的区别:
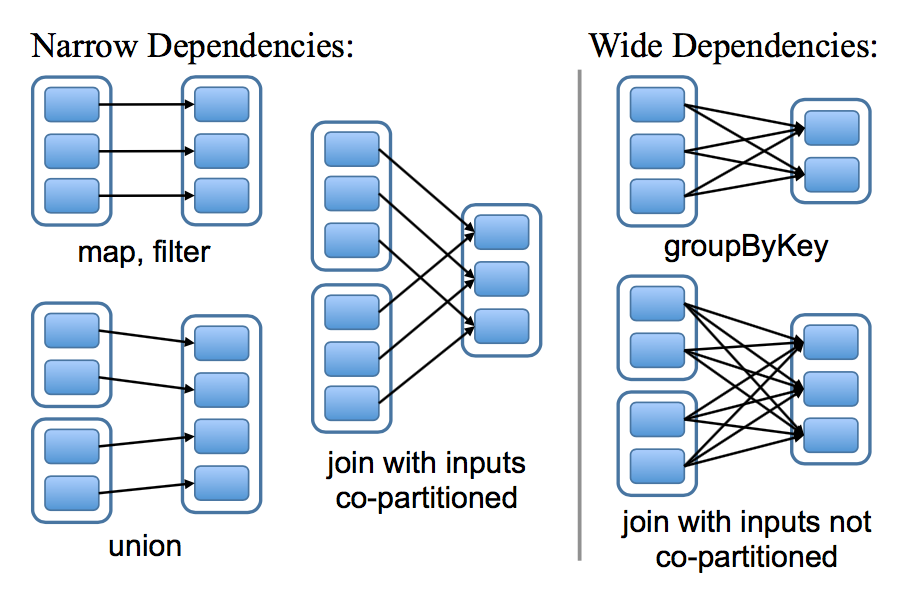
宽依赖和窄依赖¶
窄依赖:父RDD的分区最多被子RDD的一个分区使用。从子RDD角度看,它精确知道依赖的上级RDD;
宽依赖:父RDD的一个分区会被子RDD的多个分区使用。从子RDD角度看,每个分区都要依赖于父RDD的所有分区;
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖, 否则就是宽依赖。
窄依赖典型的算子包括 map 、 filter 、 union 等,宽依赖典型的算子包括 groupByKey 、 sortByKey 等。对于连接( join )操作,分为两种情况:
对输入进行协同划分(co-partitioned),属于窄依赖(如上图左所示侧)。所谓协同划分是指多个父RDD的每个分区的所有”键(key)“,落在子RDD的同一个分区上,不会产生同一个父RDD的某一分区,落在子RDD的两个分区上的情况。
对输入非协同划分(not co-partitioned),属于宽依赖,如上图右侧所示。
划为宽依赖和窄依赖有以下两个好处:
第一,窄依赖可以在单个集群节点中流水线式执行。比如,我们可以将元素应用了
map操作后紧接着应用filter操作。与此相反,宽依赖需要父亲RDD的所有分区数据都准备好,并且通过类似于MapReduce的操作将数据在不同的节点之间进行重新洗牌(Shuffle)和网络传输。第二,窄依赖从失败节点中恢复是非常高效的,因为只需要重新计算相对应的父分区数据就可以,而且这个重新计算是在不同的节点并行重计算的,与此相反,在一个含有宽依赖的DAG中,某个节点失败导致一些分区数据的丢失,但是我们需要重新计算父RDD的所有分区的数据。
Stage划分¶
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD的依赖关系来决定如何划分Stage, 具体划分方法是:从DAG图末端出发,逆向遍历整个依赖链,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的Stage中,Stage中task数目由Stage末端的RDD分区个数来决定;
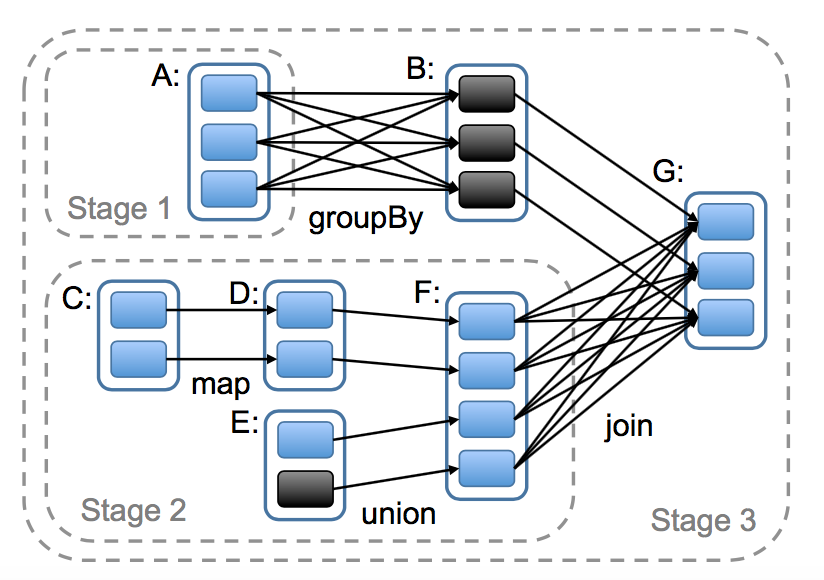
Stage划分¶
将窄依赖尽量划分在同一个Stage中,以实现流水线式计算。例如在上面的WordCount例子中,textFile、flatMap 和 map 被划分为Stage0,由于map到reduceByKey为宽依赖,所以reduceByKey和saveAsTextFile被划分为Stage1。