Spark RDD 持久化¶
Spark可以将RDD持久化到内存或磁盘文件系统中,把RDD持久化到内存中可以极大地提高迭代计算以及各计算模型之间的数据共享。
Spark的开发调优有一个原则,即对多次使用的RDD进行持久化(或称缓存)。如果要对一个RDD进行持久化,只要对这个RDD调用 cache 或 persist 即可。
cache方法¶
语法:
cache(): this.type = persist()
cache() 方法使用非序列化的方式直接将RDD的数据全部尝试持久化到内存中, cache 是 persist 的一个特例。
persist方法¶
语法:
persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
persist(newLevel: StorageLevel): this.type
persist() 方法可以手动传入一个持久化级别进行持久化,无参调用时等同于 cache() 。
持久化级别¶
persist() 方法可以传入一个 StorageLevel(持久化级别),当 StorageLevel 为 MEMORY_ONLY 时就是 cache()。
所有支持的 StorageLevel 列表定义在 StorageLevel 的伴生对象中,如下:
/**
* Various StorageLevel defined and utility functions for creating new storage levels.
*/
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
}
StorageLevel 类的五个初始化参数为:
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
因此可以将上面的持久化级别整理为:
StorageLevel |
磁盘 |
内存 |
OffHeap |
反序列化 |
副本 |
|---|---|---|---|---|---|
|
否 |
否 |
否 |
否 |
1 |
|
是 |
否 |
否 |
否 |
2 |
|
是 |
否 |
否 |
否 |
1 |
|
否 |
是 |
否 |
是 |
1 |
|
否 |
是 |
否 |
是 |
2 |
|
否 |
是 |
否 |
否 |
1 |
|
否 |
是 |
否 |
否 |
2 |
|
是 |
是 |
否 |
是 |
1 |
|
是 |
是 |
否 |
是 |
2 |
|
是 |
是 |
否 |
否 |
1 |
|
是 |
是 |
否 |
否 |
1 |
|
是 |
是 |
是 |
否 |
1 |
例如:
MEMORY_ONLY:将RDD以未序列化的Java对象格式储存在内存中。如果内存不够存放所有的数据,则某些分区将不会被缓存。
MEMORY_AND_DISK:将RDD以未序列化的Java对象格式存储在内存中。如果内存不够存放所有的数据,则将剩余存储在磁盘中。
MEMORY_ONLY_SER / MEMORY_AND_DISK_SER:基本含义同 MEMORY_ONLY / MEMORY_AND_DISK 。唯一的区别是,它会将RDD中的数据进行序列化,这样更加节省内存,从而可以避免持久化的数据占用过多内存导致GC。
DISK_ONLY:将RDD以未序列化的Java对象格式写入磁盘文件中。
例子¶
这里以搜狗日志数据为例,计算用户一天的搜索条数,数据从搜狗实验室(http://www.sogou.com/labs/) 下载 。
将下载后的数据包解压上传至HDFS:
hdfs dfs -put SogouQ.reduced /data
然后在spark-shell中执行:
scala> val sc = spark.sparkContext
sc: org.apache.spark.SparkContext = org.apache.spark.SparkContext@70cc0601
scala> val fileRdd = sc.textFile("hdfs://127.0.0.1:9000/data/SogouQ.reduced", minPartitions = 1)
fileRdd: org.apache.spark.rdd.RDD[String] = hdfs://127.0.0.1:9000/data/SogouQ.reduced MapPartitionsRDD[1] at textFile at <console>:25
scala> fileRdd.cache()
res0: fileRdd.type = hdfs://127.0.0.1:9000/data/SogouQ.reduced MapPartitionsRDD[1] at textFile at <console>:25
scala> fileRdd.count()
res1: Long = 1724264
scala> fileRdd.count()
res2: Long = 1724264
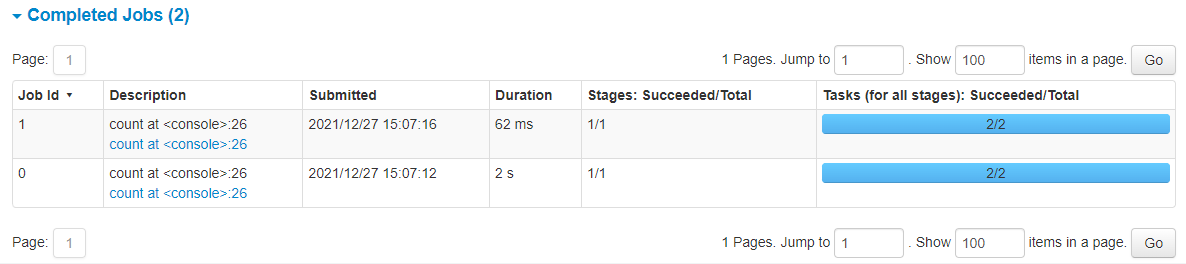
在代码中,第一次 count 时会从HDFS中读取数据,然后将这些数据缓存在内存中;第二次 count 时就直接从内存中读取数据。
可以在UI界面看到,第一次 count 耗时2s,第二次 count 只耗时62ms。